El corpus de confusión consistente del inglés oral
En la percepción del habla con ruido de fondo a menudo se producen errores en los que el oyente cree haber escuchado una palabra distinta de la pronunciada. Este fenómeno se ha llamado «deslices del oído» (slips of the ear). Un grupo en el que trabaja la profesora de la UPV/EHU María Luisa García Lecumberri ha generado el primer gran corpus de errores de percepción coincidentes para el inglés, que abarca más de 3.000 términos y está disponible on line.

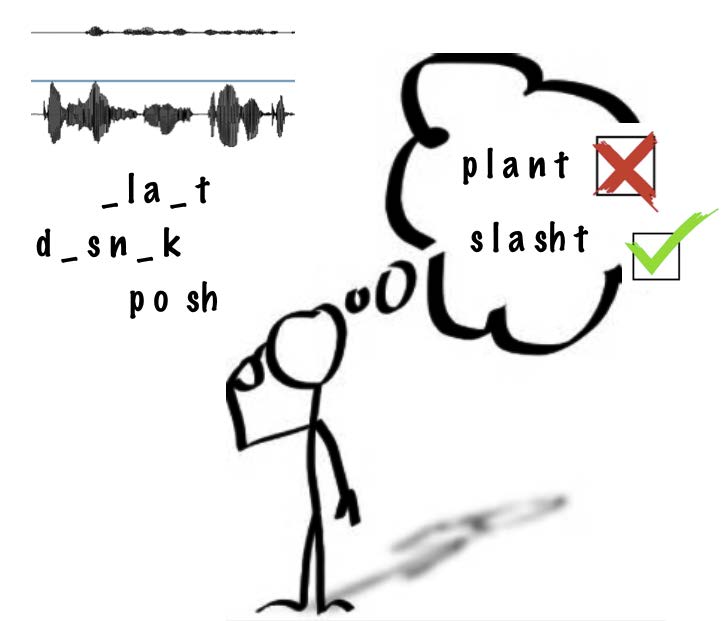
Normalmente no oímos en condiciones óptimas -hay ruidos de fondo como tráfico, máquinas, otras conversaciones- pero, como hablantes nativos y ayudados por el contexto, tenemos capacidad para reconstruir la parte de la señal que no nos ha llegado. Sin embargo, ello no evita que cometamos errores. El grupo que integran María Luisa García Lecumberri, el profesor Ikerbasque de la UPV/EHU Martin Cooke y los investigadores de la Universidad de Sheffield Jon Barker y Ricard Marxer ha identificado 3.207 percepciones erróneas coincidentes para el inglés, es decir, errores en los que un número significativo de oyentes coinciden. Estas concordancias tienen valor como tests de los modelos de percepción del habla y para comprender mejor cómo funcionan los mecanismos de percepción de los humanos.
Para ello realizaron un estudio a gran escala con 212 participantes y más de 300.000 presentaciones de palabras, que los investigadores sacaban de contexto, es decir, las presentaban de forma aislada con ruido de fondo. El estudio logró identificar 3.207 percepciones erróneas coincidentes y las ha reunido en un corpus, único en su categoría y que está disponible online: http://spandh.dcs.shef.ac.uk/ECCC/. Para cada una de las percepciones erróneas, el corpus presenta las ondas sonoras de la palabra pronunciada y del ruido de fondo que generó el error, las respuestas aportadas por los oyentes y las transcripciones fonémicas de la palabra pronunciada y de la percibida. Se observó que hay distintos tipos de confusiones. En algunos casos está claro que el ruido ocultaba parte de la palabra y los oyentes imaginaban otra palabra que coincidía con las partes audibles («wooden –> wood» o «pánico» –> «pan») o sustituían las partes inaudibles por otros sonidos («ten» –> «pen» y «valla –>falla»). En otros casos se reconstruían la palabra incorporando fragmentos del ruido o conversaciones de fondo, («purse –> permitted» o «ciervo» –> «invierno»). Finalmente se encontraban percepciones extrañas pero con coincidencia de varios hablantes, en las que no había ninguna similitud entre la palabra emitida y la que creían haber óido, («modern –> suggest» o «guardan –> pozo»). En estos casos la interacción entre habla y ruido es bastante más compleja y, por lo tanto, interesante.
«Estos estudios nos ayudan a comprender mejor los mecanismos de percepción del habla, y cuanto mejor conozcamos dichos mecanismos, mejor se podrá ayudar, a nivel técnico y clínico, a los que padecen problemas de percepción», indica la investigadora. El grupo publicó anteriormente un corpus de deslices de oído del castellano, que también puede ser consultado en el mismo sitio web. «Entre ambos hay similitudes y diferencias: el castellano es una lengua con más flexión, lo cual provoca que haya más confusiones en las terminaciones; el inglés tiene más monosílabos y más riqueza consonántica en posición final, donde se producen más errores en los que se sustituye una consonante por otra», añade. Coinciden ambas lenguas en que, dependiendo del tipo de ruido, sobreviven mejor unos tipos de sonidos y sílabas que otros.
Ricard Marxer, Jon Barker, Martin Cooke, and Maria Luisa Garcia. A corpus of noise-induced word misperceptions for English. The Journal of the Acoustical Society of America Volume 140, Issue 5. doi: 10.1121/1.4967185.
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa