El aprendizaje continuo mejora la interacción de robots con humanos en lenguaje natural
Los sistemas de diálogo son esenciales para que los robots interactúen con las personas en lenguaje natural. Para mejorar estas interacciones con el paso del tiempo, el sistema debe de ser capaz de aprender de sus experiencias, de sus errores y del feedback con la persona usuaria. Este proceso de aprendizaje continuo es la base del proyecto europeo LIHLITH, que lideran los grupos de investigación IXA y RSAIT de la UPV/EHU y financia el programa europeo CHIST-ERA.

La inteligencia artificial es un campo que progresa rápidamente en múltiples áreas, incluyendo los diálogos con máquinas y robots. Ejemplo de ello es que en la actualidad es posible hablar a un dispositivo para solicitarle tareas tan simples como apagar la radio o preguntarle por el tiempo; pero también se ha conseguido que hagan tareas más complejas, como que la máquina llame a un restaurante para hacer una reserva o que un robot atienda a los clientes de una tienda.
El proyecto europeo LIHLITH (Learning to Interact with Humans by Lifelong Interaction with Humans) “es un proyecto orientado a avanzar en los diálogos entre personas y máquinas, cuyo objetivo es mejorar las capacidades de autoaprendizaje de la inteligencia artificial”, explica Eneko Agirre, investigador de la UPV/EHU. Concretamente, en el proyecto LIHLITH se van a tratar sistemas de diálogo que aprenden y mejoran en función de sus interacciones con los humanos. Se trata de un proyecto europeo de tres años, que fue puesto en marcha en enero del 2018, financiado por el programa europeo CHIST-ERA y dirigido por los grupos de investigación IXA y RSAIT de la Facultad de Informática de la UPV/EHU. El proyecto cuenta con la participación de la UPV/EHU, del Laboratorio de Informática para la Mecánica y la Ingeniería (LIMSI, Francia), de la UNED, de la Universidad de Ciencias Aplicadas de Zurich (ZHAW) y de Synapse Développement (Francia).
Los chatbots o los bots conversacionales son programas informáticos que siguen una conversación utilizando métodos textuales o auditivos. Los chatbots industriales actuales se basan en reglas que deben elaborarse de forma manual y minuciosa para cada dominio de aplicación. Por otra parte, los sistemas basados en el aprendizaje automático utilizan datos del dominio anotados manualmente, que permiten entrenar el sistema de diálogo. Tanto para elaborar las reglas como para los datos de entrenamiento de cada dominio de diálogo se necesita mucho tiempo, por lo que limitan la calidad y la difusión de los chatbots. Además, las empresas necesitan monitorizar el rendimiento del sistema de diálogo antes de implementarlo, así como rediseñarlo para que responda a las necesidades de la persona usuaria. “En el proyecto LIHLITH se va a explorar el paradigma del aprendizaje continuo en sistemas de diálogo entre personas y máquinas, con el objetivo de mejorar su calidad, de reducir los costes de mantenimiento y de disminuir los esfuerzos para utilizarlos en nuevos dominios”, añade Agirre, principal investigador del proyecto.
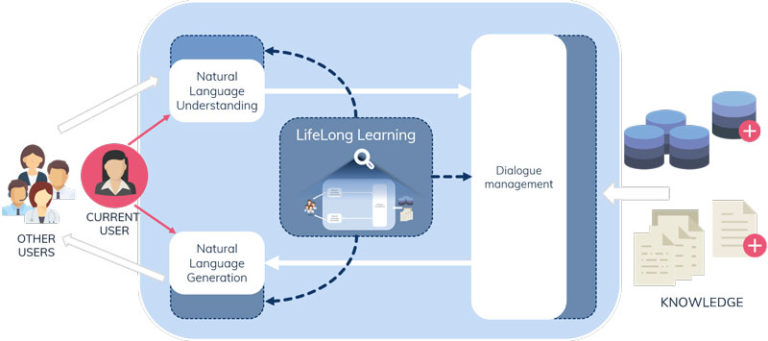
Los sistemas de dialogo estándar utilizan la comprensión de lenguaje natural para procesar la entrada del usuario, la gestión del diálogo para acceder al conocimiento del dominio y decidir qué respuesta va a dar, y la generación del lenguaje natural para emitir la respuesta del sistema. El principal objetivo de los sistemas de aprendizaje continuo es que sigan aprendiendo incluso después de ser implementados. En el caso de LIHLITH, “el sistema de diálogo se desarrollará como de costumbre, pero se incluirá un mecanismo que le permitirá continuar mejorando sus capacidades en función de su interacción con las personas usuarias —apunta Agirre—. La clave es que los diálogos estarán diseñados para recibir el feedback de las personas usuarias, y el sistema aprenderá de este feedback continuo. Esto permitirá al sistema mejorar continuamente a lo largo de su vida, adaptándose rápidamente a los cambios de dominio que ocurren después de ser implementado”.
LIHLITH estará orientado a “diálogos de preguntas y respuestas enfocados a lograr un objetivo, en los que la persona usuaria necesita una información y el sistema intentará satisfacer dicha necesidad mientras conversa con ella”, añade. Para ello, el proyecto trabajará en tres áreas de investigación: el aprendizaje continuo para el diálogo; el aprendizaje continuo para la inducción del conocimiento y la respuesta a preguntas; y la evaluación de la mejora del diálogo. “Todos los módulos serán diseñados para aprender del feedback disponible mediante técnicas de aprendizaje profundo. La clave innovadora del proyecto LIHLITH está en el módulo de aprendizaje continuo, que mejorará todos los módulos a medida que el sistema interactúa con las personas, actualizando el conocimiento del dominio”, comenta. El proyecto explorará la reconfiguración autónoma de estrategias de diálogo y las capacidades proactivas para solicitar a la persona usuaria nuevos conocimientos.
Para llevar a cabo esta investigación, LIHLITH combina el aprendizaje automático, la representación del conocimiento y la experiencia lingüística. El proyecto contará con avances obtenidos recientemente en numerosas disciplinas, incluyendo el procesamiento del lenguaje natural, el aprendizaje profundo, la inducción de conocimiento, el aprendizaje reforzado y la evaluación de diálogo, con los que se explorará su aplicabilidad en el aprendizaje permanente.
Referencia:
Eneko Agirre, Sarah Marchand, Sophie Rosset, Anselmo Peñas, Mark Cieliebak (2018) LIHLITH: Improving Communication Skills of Robots through Lifelong Learning. ERCIM News No. 114, Special theme: Human-Robot Interaction.
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
Hitos en la red #228 – Enlaces Covalentes
[…] El aprendizaje continuo mejora la interacción de robots con humanos en lenguaje natural […]